Overview - Document Intelligence
| Participate in the new Red Team competition track on: Inference Attacks Against Document VQA (organised in the context of SaTML 2025) |
Privacy-Preserving Federated Learning Document VQA
The objective of the Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition is to develop privacy-preserving solutions for fine-tuning multi-modal language models for document understanding on distributed data. We seek efficient learning solutions for finetuning a pre-trained generic Document Visual Question Answering (DocVQA) model on a new domain, that of invoice processing.
Automatically managing the information of document workflows is a core aspect of business intelligence and process automation. Reasoning over the information extracted from documents fuels subsequent decision-making processes that can directly affect humans, especially in sectors such as finance, legal or insurance. At the same time, documents tend to contain private information, restricting access to them during training. This common scenario requires training large-scale models over private and widely distributed data.
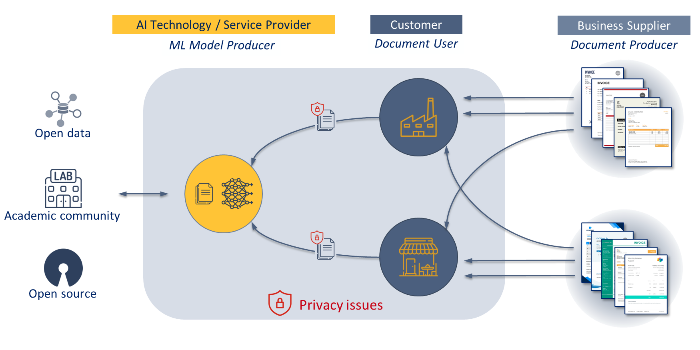
These models are especially vulnerable to leakage of private data, and so are especially relevant in the contexts of privacy risks and privacy-preserving ML. We also provide a competition framework to encourage the implementation of practical methods that expose such privacy vulnerabilities, with the aim of better understanding real-world threat models and the robustness of differential privacy in multimodal models.
This competition is therefore organised in two parts:
- The Blue Team Challenge invites the development of effective and efficient algorithms for training federated DocVQA models in a privacy-preserving manner.
- The Red Team Challenge invites the development of novel privacy attacks to test the privacy-preserving properties of these models.
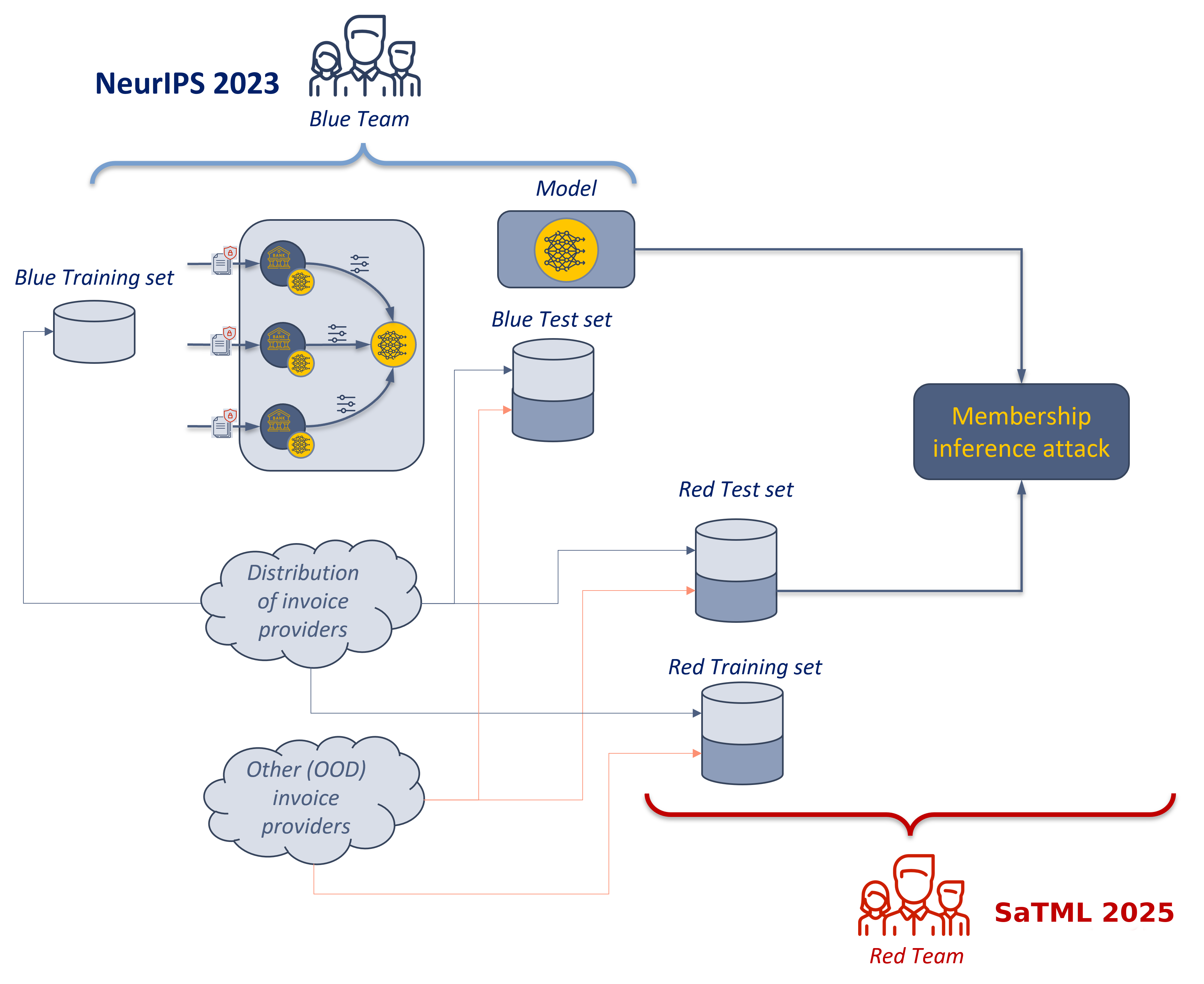
Blue Team Challenge
NeurIPS 2023 Competition on Privacy Preserving Federated Learning Document VQA
This challenge invites the development of methods to train Document Visual Question Answering models on the provided documents with privacy guarantees, using a federated-learning set-up. The challenge is further subdivided in 2 different tracks:
- Track 1 - Federated Learning only: The methods will be trained within a federated learning framework, simulating the need for cooperation between different entities to achieve the best performing model in the most efficient way. Track 1 participant's objective is to reduce the communication used (#bytes), while achieving a comparable performance with the baseline.
- Track 2 - Federated Learning + Privacy-preserving: In this track, in addition to training over distributed data, we seek to protect the identity of providers that could be exposed to textual (provider company name) or visual (logo, presentation) information. If a malicious competitor (adversary) manages to infer information about a company's providers, it could have a direct impact on the company's business.
This challenge was hosted in the context of NeurIPS 2023, and has concluded. See Blue Team Participation Instructions for details on the submitted results and winning methods.
PFL-DocVQA Workshop at NeurIPS 2023
We hosted a half-day workshop at NeurIPS 2023 on Friday 15 Dec., from 7 a.m. to 10 a.m. PST in hybrid format.
Check out the slides and videos of our NeurIPS 2023 workshop.
Red Team Challenge
SaTML 2025 Competition: Inference Attacks Against Document VQA
This challenge invites the development of inference attacks to extract sensitive information from Document Visual Question Answering models. The challenge is further subdivided in 2 different tracks:
- Track 1 - Membership Inference Attacks: Participants' objective is to attack a trained DocVQA model by determining the training set membership of individual document providers. That is, they must use the output of the model to classify whether specific suppliers are part of the training data or not.
- Track 2 - Reconstruction Attacks: Participants' objective is to attack a trained DocVQA model by extracting memorised information from specific documents. That is, they must recover information from documents that was seen during training but is not available at test time.
This challenge is hosted in the context of SaTML 2025. It is currently under construction and details will be finalised soon - please stay tuned.
Results will be presented at the conference on April 9-11. See Red Team Participation Instructions for details on how to participate.
Contact information
For any questions about this competition, please contact info_pfl@cvc.uab.cat
Publications
-
Rubèn Tito, Khanh Nguyen, Marlon Tobaben, Raouf Kerkouche, Mohamed Ali Souibgui, Kangsoo Jung, Lei Kang, Ernest Valveny, Antti Honkela, Mario Fritz, and Dimosthenis Karatzas. Privacy-Aware Document Visual Question Answering on arXiv 2023 [arxiv:2312.10108]
Citation
If you use this dataset or code, please cite our paper.
@article{tito2023privacy,
title={Privacy-Aware Document Visual Question Answering},
author={Tito, Rub{\`e}n and Nguyen, Khanh and Tobaben, Marlon and Kerkouche, Raouf and Souibgui, Mohamed Ali and Jung, Kangsoo and Kang, Lei and Valveny, Ernest and Honkela, Antti and Fritz, Mario and Karatzas, Dimosthenis},
journal={arXiv preprint arXiv:2312.10108},
year={2023}
}
Challenge News
- 09/01/2024
New Competition Track at SaTML - 10/11/2023
ELSA sponsored prizes for winners announced - 09/15/2023
Workshop at NeurIPS 2023 - 08/17/2023
Communications log fixed in baseline code - 07/21/2023
Final version of the PFL-DocVQA framework released - 06/30/2023
Release of training and validation splits.
Important Dates
September 2, 2024: Competition Web online.
October 14, 2024: Competition opens.
March 7, 2025: Submission deadline for entries.
March 17, 2025: Announcement of winning teams.
April 9-11, 2025: Competition track (during SaTML).